
From Build to Production: Introducing Agent Evaluation for Continuous Improvement
Data-driven evaluation, automated regression testing, and intelligent model comparison empower enterprises to nurture agents with confidence at every stage of the lifecycle
We're thrilled to announce a powerful new capability in Karini AI's Agentic Foundation platform, Agent Evaluation. As enterprises accelerate their journey from experimental AI projects to production-grade agentic systems, a critical gap has emerged, the need for systematic, repeatable evaluation that keeps pace with the dynamic nature of generative AI.
The Evolution of Evaluation Capabilities in Karini AI
Karini AI has long recognized that building AI systems is only half the battle, measuring and optimizing their performance is what separates production-ready solutions from promising prototypes.
Our journey began with Agent Optimization, which enabled practitioners to fine-tune agent behavior through systematic hyperparameter tuning to recommend the most suitable LLM for the task. We then expanded these capabilities with Recipe Workflow Evaluation, allowing teams to validate complete end-to-end workflows and measure how multi-step processes perform against business expectations.
But as our customers deployed increasingly sophisticated agentic architectures, a new challenge emerged. Modern Agentic workflows are compound systems, intricate orchestrations of multiple prompts, agents, and decision points working in concert. When a workflow underperforms, the question becomes: which component is responsible? When a foundational model changes, which steps are affected? When an edge case surfaces, which prompt needs adjustment?
Evaluating workflows as monolithic units provides valuable signals, but compound systems demand granular insight. Each prompt, each agent, each decision node represents a potential point of optimization or failure. To truly nurture these systems at scale, enterprises need the ability to regression test each step independently.
Prompt and Agent Evaluation completes this picture, enabling component-level testing that complements our existing workflow evaluation capabilities. Now practitioners can drill down from end-to-end workflow metrics to understand exactly how individual prompts and agents contribute to overall system behavior.
The New Challenge: Agent Nurturing at Scale
Building an agent is just the beginning. The real work starts when that agent goes live. Production agents are living systems that require continuous nurturing, and enterprise teams are discovering that traditional testing approaches simply don't cut it.
Consider the reality facing AI practitioners today: Your carefully crafted prompts perform brilliantly against your test cases, but how do you know they'll hold up against the diversity of real-world inputs? Your production agent has been humming along for months, but the foundational model it relies on is approaching end-of-life. An edge case surfaces in production that requires prompt adjustments, but will those changes break the 47 other scenarios that were working perfectly?
These aren't hypothetical concerns. They're the daily reality of enterprise AI teams managing agents at scale.
Introducing Agent Evaluation
Karini AI's Evaluation feature provides a robust framework for testing and measuring the performance of your agents through automated, data-driven assessment. It transforms the art of prompt engineering into a measurable science, enabling teams to validate, compare, and optimize with confidence.
Our evaluation framework addresses three critical scenarios that emerge as agents move into production:
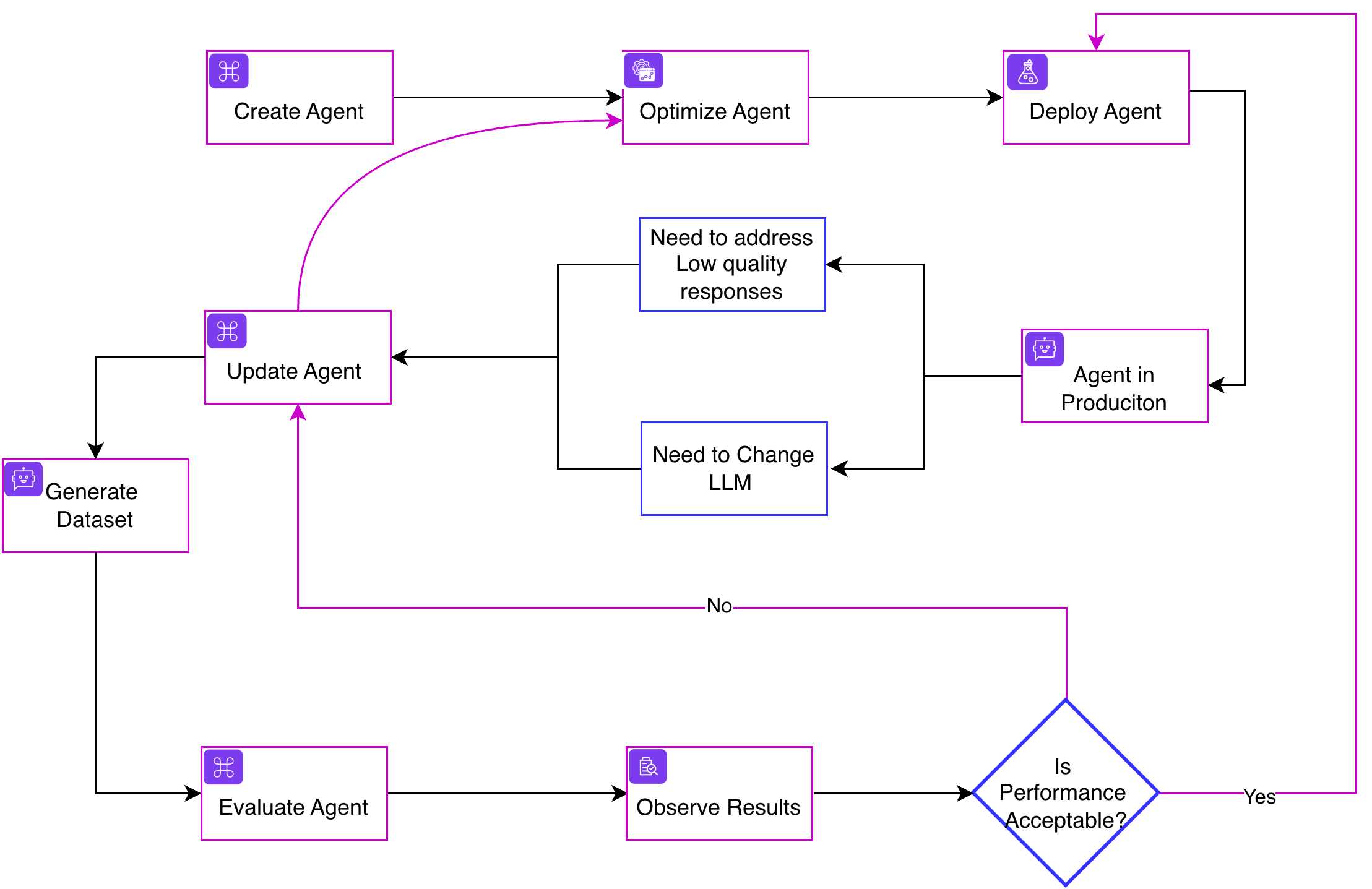
1. Validate During Build: Human-Curated Benchmark Testing
The journey to production begins with validation. Karini AI's Evaluation enables builders to test prompts and agents against curated datasets that reflect the nuanced expectations of your business domain.
Rather than relying on intuition or spot-checking, practitioners can now systematically compare agent performance against human-curated ground truth. Upload your golden datasets the examples that represent exactly how your agent should respond and let the evaluation framework measure alignment across multiple dimensions.
2. Navigate Model Transitions: Find Your Next Best Candidate
The Agentic AI landscape evolves rapidly. LLMs that power your production agents today may be deprecated tomorrow, and newer models with improved capabilities emerge constantly. But swapping models isn't a simple configuration change, it can fundamentally alter agent behavior.
Karini AI's Evaluation framework employs LLM-as-a-judge approach with both standard and custom metrics, enabling side-by-side comparison of how different models perform against your specific use cases. When your current model approaches end-of-life, you can systematically evaluate candidates against your production workloads before making the switch.
This capability transforms model migration from a high-stakes gamble into a data driven decision. Compare latency, accuracy, consistency, and custom business metrics across model candidates, then promote the best performer with confidence.
3. Evolve Safely: Automated Regression Testing for Continuous Improvement
Production agents encounter scenarios that no amount of pre-launch testing can fully anticipate. When outlier cases emerge requiring prompt adjustments, the question becomes: how do you improve without regressing?
Our evaluation framework enables automated regression testing that validates changes against your complete test corpus. Tweak a prompt to handle a new edge case, then automatically verify that existing scenarios continue to perform as expected. The framework captures detailed analytics, enabling builders to understand not just whether performance changed, but how and where.
Because compound workflows depend on the reliable performance of every component, the ability to test prompts and agents in isolation is essential. A subtle degradation in one agent's response quality can cascade through downstream steps, amplifying into significant workflow-level failures. Independent component testing catches these issues at their source.
How It Works
Karini AI's Evaluation is designed for practitioners who need power without complexity:
Step1: Upload Dataset: Select your golden set of examples curated from historical conversations. You can also use Karini’s Chat or Webhook history to filter and generate the dataset.
Step2: Select Evaluation Strategy: Choose from standard evaluation metrics or define custom criteria that reflect your unique quality requirements. The LLM-as-a-judge approach enables nuanced assessment that goes beyond simple string matching.
Step3: Hit Run: Evaluate published Agent versions against as scale and take a coffee break and come back to see the results.
Step4: Review Results: Detailed results provide the insights needed to diagnose issues and prioritize improvements. Move beyond "pass/fail" to understand the specific dimensions where agents excel or need attention.
A Complete Evaluation Strategy
With Prompt and Agent Evaluation, Karini AI now offers a comprehensive evaluation strategy that matches the complexity of modern agentic architectures:
| Situation | Capability | What It Measures |
|---|---|---|
| Regression test Agent changes or LLM upgrades | Prompt and Agent Evaluation | Individual prompt/agent performance against curated datasets that benchmarks LLM against Ground Truth. |
| Regression test Workflow changes | Recipe Workflow Evaluation | End-to-end workflow evaluation that may include one to many nodes such as Agents, prompts or custom functions. |
| Need to identify best LLM for the task to reduce cost and improve latency | Agent Optimization | Iterates over variants of agentic prompts against candidate LLMs using sample dataset to come up improved prompt and LLM to reduce cost and improve latency. |
This layered approach enables teams to diagnose issues at the right level of abstraction, zooming out to understand system-wide patterns, or drilling in to pinpoint specific component behaviors.
The Path Forward
The transition from experimental AI to production-grade systems demands new approaches to quality assurance. Point-in-time testing isn't enough when agents must perform reliably across millions of interactions. Manual review doesn't scale when dozens of agents require continuous attention. And workflow-level evaluation alone cannot pinpoint which component in a complex system requires attention.
Karini AI's Agent Evaluation transforms how enterprises approach agent quality. By making evaluation systematic, automated, and data-driven, at every level of the compound system, we're enabling teams to nurture agents with the same rigor they apply to any mission-critical system.
Ready to bring evaluation rigor to your agentic workflows? Experience how Karini AI's Prompt and Agent Evaluation can help you build, deploy, and nurture agents with unprecedented confidence.
Karini AI: Building Better Agentic AI, Faster.