
Latency and cost are significant challenges for organizations building applications on top of Language Models. High latency can severely degrade user experience, while increased costs hinder scalability and long-term viability. Imagine an LLM application processing thousands of API calls every hour, where users frequently ask similar questions that have already been answered. Each redundant call to the LLM incurs additional costs and results in a suboptimal user experience. This situation becomes particularly problematic when hundreds of users repeat the same question. Karini AI's managed semantic cache significantly reduces these high costs, ensuring a more sustainable financial model for your applications.
What if a system could retrieve precomputed answers from a cache instead of re-executing the entire inference process? Semantic caching addresses this need by storing previously generated responses and serving them when similar queries are made. This is achieved through tokenization and similarity measures, which allow the system to intelligently match and serve similar queries from the cache. This approach reduces latency, improves response times, and significantly cuts operational costs by eliminating the need for repeated token processing. A semantic cache can transform LLM-based applications' efficiency and user experience, making them more scalable and cost-effective.
Karini AI now incorporates managed semantic cache to enhance generative AI applications, and it can be enabled with a single click.
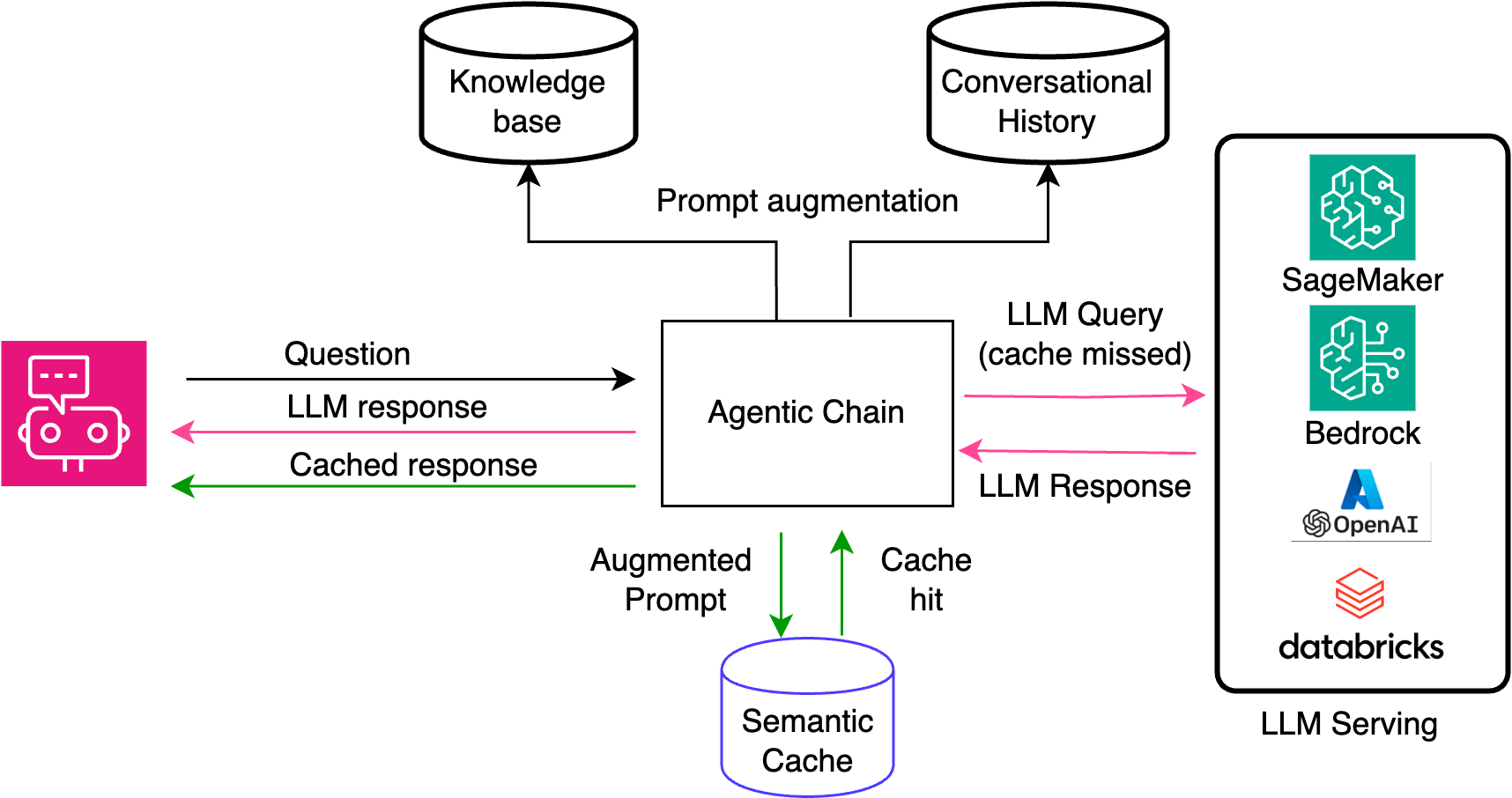
With Karini AI’s managed semantic cache, you can achieve:
- Cost optimization: Serving responses without invoking LLMs can save substantial costs. Customers have reported that the caching layer can handle 20-30% of user queries in some use cases.
- Improvement in latency and query response throughput: Serving responses from a cache is much faster than generating them in real time through LLM inference. This leads to quicker response times, enhancing user experience by providing instant answers to frequently asked queries. With Karini AI's semantic caching capabilities, you can expect a significant boost in the efficiency of your applications, with faster response times becoming the norm and ensuring user satisfaction.
- Consistency in responses: By serving answers from the cache, the LLM does not need actual generation each time a similar query is made. This means that queries deemed semantically similar will always receive the same response, ensuring uniformity and reliability in user information and providing a sense of security.
- Optimized query handling: Semantic caching employs similarity measures to retrieve semantically similar queries from the cache. This means that even if the question hasn't been asked, the system can intelligently match and answer similar questions from the cache, reducing the need for LLM inference.
- Scaling: Because cache hits, successful retrievals of precomputed answers from the cache respond to questions without invoking LLMs, the provisioned resources and endpoints are available to address new or unseen user queries. This means that as your user base grows, your application can continue to provide fast and reliable responses, without the need for additional resources. This is particularly beneficial when scaling applications to accommodate a more extensive user base, ensuring that your application can handle increased traffic without compromising performance.
- Enhanced user experience: Faster response times and reliable answers from the cache improve overall user satisfaction. Users receive swift responses to their queries, particularly important in applications requiring real-time interactions.
Semantic caching is vital in LLM-based applications as it reduces costs, improves performance, and enhances scalability, reliability, and user experience. By efficiently managing and serving cached responses, applications can more effectively leverage the power of LLMs. With Karini AI, you can develop innovative, reliable, cost-effective AI applications by leveraging semantic caching.




