
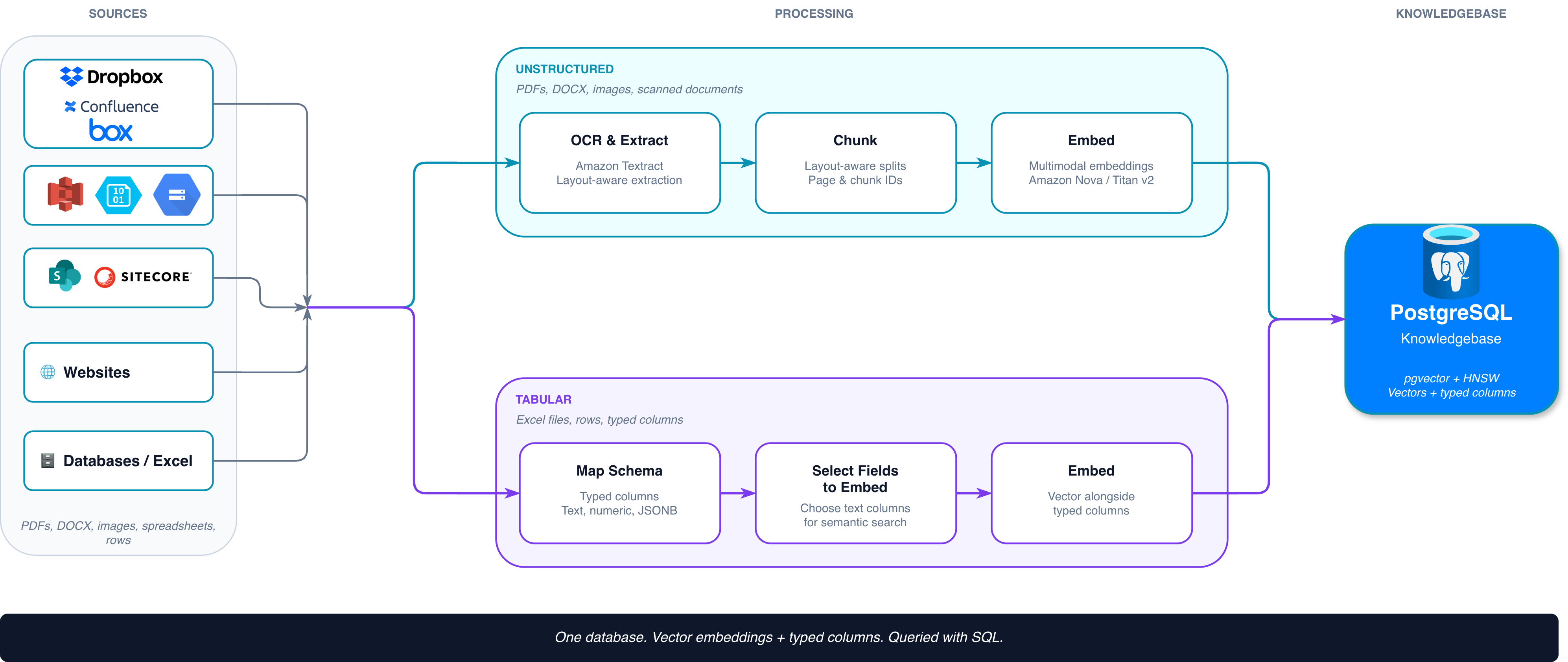
Enterprise data does not arrive in a single shape. A construction bid history lives in Excel spreadsheets stored in Box. A spare parts catalog lives in a relational database. A library of service manuals lives in PDFs and engineering drawings. A product taxonomy lives in tables with hundreds of typed columns. And across all of it, business users expect to ask one question "what is the cost history for stainless steel fittings on healthcare projects in the Midwest?" and receive one grounded answer.
Most enterprise AI architectures handle this by running two systems. A vector database for semantic search over documents, and a relational database for structured queries over tabular data. Engineering teams then write glue code to query both, merge the results, and hope the rankings make sense. The operational cost is real. The data drift between the two stores is worse.
We think there is a better way. What if the same database that already holds your structured business data could also serve your unstructured documents and the embeddings on top of them?
Today we are adding PostgreSQL as a Knowledgebase provider on the Karini AI platform. Backed by pgvector with HNSW indexing, the Postgres provider serves both unstructured documents and tabular data from a single store and plugs directly into agents as both a Knowledgebase node and an Agentic tool.
Why Postgres Belongs in the Knowledgebase Conversation
Vector databases are excellent at one job: finding semantically similar passages from large document collections. They are not built for typed columns, joins, range filters, or the structured queries that most enterprise data demands. When the question requires both
"find similar bids where the project type matched and the contract value was between $2M and $10M"
pure vector stores cannot answer it without external orchestration.
Postgres approaches the problem from the other direction. It has been the world's most capable relational database for decades. With the pgvector extension, it now stores and indexes embeddings as first-class column types alongside everything else. The result is a single database engine that can:
-
Hold document embeddings and run semantic search using cosine similarity, accelerated by HNSW indexes
-
Store tabular data with real typed columns including text, numerics, booleans, JSONB, and vectors
-
Apply filters, joins, access controls, and metadata constraints using the SQL engine your team already knows
-
Express precise retrieval logic that pure vector stores cannot - semantic similarity combined with structured filters in a single query
For organizations that already operate Postgres for application data, this collapses the retrieval stack. No new datastore to provision. No second backup strategy. No sync pipeline between vector store and source of truth.
What the Postgres Provider Supports
The Karini AI Postgres Knowledgebase provider exposes a complete lifecycle over both data types. The platform handles ingestion, indexing, retrieval, and operations through a single interface, regardless of whether the underlying data is documents, tables, or both.
| Capability | Description |
|---|---|
| Document ingestion | Chunking with page numbers, chunk IDs, and raw chunk tracking. Embedding generation in bulk with batched inserts. |
| Tabular ingestion | Dynamic table creation with typed columns and user-supplied column mappings. Supports text, integer, float, boolean, JSONB, and vector types. |
| Vector search | Cosine similarity search accelerated by HNSW indexes (m=16, ef_construction=200). Default 1536-dimensional embeddings, configurable per workload. |
| Filtering & access control | ACL-based access control using JSONB tag filtering. Metadata filtering with must, should, and must-not clauses. Case-insensitive keyword filtering on source references. |
| Hybrid retrieval | Semantic similarity combined with structured filters and joins in a single query, expressible through SQL templates with platform-managed parameters. |
| Operations | Index lifecycle management, item-level deletion, chunking-type deletion, full index drop, and introspection of indices, items, and mappings. |
| Credentials | Inline properties, AWS Secrets Manager integration, or environment variables, selectable per deployment. |
Indexes are created as kb_{dataset_id} tables, with connection pooling provided out of the box for concurrent agent workloads.
How It Fits Alongside the Other Providers
Postgres is not a replacement for the other Knowledgebase providers on the Karini AI platform. Each provider has its own strengths, and the right choice depends on the workload.
| Provider | Best for |
|---|---|
| OpenSearch | Full-text and hybrid (BM25) search, rich query DSL, large-scale document collections |
| Azure AI Search | Managed vector search on Azure with native integration into Microsoft data services |
| PostgreSQL (new) | Unstructured documents and tabular data in one database, with SQL-level retrieval control |
Reach for OpenSearch when your priority is advanced full-text and hybrid search at scale. Reach for Azure AI Search when you are standardizing on their respective platforms. Reach for Postgres when your data is already relational, when you want one operational footprint for retrieval, or when your queries need the precision that SQL provides over vector-only stores.
Using Postgres in Agents
Once your knowledgebase lives in Postgres, agents on the Karini AI platform can use it two ways.
The first is as a Knowledgebase node inside an agentic workflow. The node is configured to point at the Postgres provider, and the agent retrieves grounded context as part of its reasoning. While retrieval runs, end users see a transparent status indicator "Searching {your knowledgebase}" so the workflow remains observable.
The second is as an Agentic tool that the model can call on demand. The agent passes a natural-language query, the platform embeds it, runs the retrieval, and returns the ranked results. For advanced workflows, power users can supply a SQL query template with platform-managed placeholders for query text and result count. This unlocks precise control over joins, filters, and ranking that pure vector stores cannot express. Queries run with timeout protection so that a slow query never hangs an agent.
The result is that a single agent can do semantic retrieval and structured lookups against the same knowledgebase, in a single tool call, against a single database.
See It in Action
To demonstrate the Postgres Knowledgebase provider end to end, we have built three short walkthroughs across the Karini AI platform.
Step 1. Create a Postgres Knowledge Base with unstructured PDFs
Step 2. Create a Postgres Knowledge Base with Excel files in Box folder
Step 3. Build Agentic RAG with Postgres as a Knowledge Base Tool
Benefits of the Postgres Knowledgebase Provider
The Postgres provider is built for the operational realities of enterprise data teams that already trust Postgres and want their retrieval layer to follow.
| Benefit | Impact |
|---|---|
| One Database for All Data Shapes | Documents, embeddings, and tabular data live in the same store. No sync pipelines between vector store and source of truth, no drift between systems, no second backup strategy. |
| SQL-Native Retrieval Precision | Hybrid queries that combine semantic ranking with structured filters, joins, and ranking logic that pure vector stores cannot express. Power users can supply query templates for exact control. |
| Operational Continuity | Teams that already run Postgres reuse their existing expertise, tooling, monitoring, and disaster recovery. Retrieval becomes a workload, not a new datastore. |
| First-Class Tabular Support | Excel files, structured exports, and relational source data ingest as typed columns rather than being flattened into free-text blobs. The structure that makes the data useful is preserved at query time. |
| Production-Grade Vector Search | HNSW indexing with tuned defaults delivers vector search latencies appropriate for interactive agent workloads. Connection pooling handles concurrent retrieval. |
| Drop-In Agent Integration | The same knowledgebase is exposed as both a Knowledgebase node and an Agentic tool, available to every agent on the Karini AI platform without additional configuration. |
From Two Datastores to One
The enterprise AI conversation has spent the last three years assuming that vector retrieval requires a dedicated vector database. That assumption made sense when pgvector was nascent and the SQL ecosystem had not caught up to the demands of semantic search. It does not make sense today.
For a large class of enterprise workloads, bid histories in spreadsheets, document catalogs with structured metadata, product data with mixed text and typed attributes, the right answer is not a separate vector store stitched to a relational database. It is a single database that handles both natively, queried with the SQL primitives the team already knows, deployed on the operational footprint the company already trusts.
This is the shift the Postgres Knowledgebase provider enables. From two datastores to one. From glue code to SQL. From vector-only retrieval to hybrid retrieval that respects the shape of your data.
The Postgres Knowledgebase provider is available today on the Karini AI platform.
FAQ
What is the Karini AI PostgreSQL Knowledgebase provider?
The Karini AI PostgreSQL Knowledgebase provider allows enterprises to use Postgres as a retrieval layer for both structured and unstructured data. It can store document chunks, embeddings, tabular data, metadata, and access-control tags in one database, then expose that knowledgebase to agents through Karini AI workflows.
Why use PostgreSQL as a Knowledgebase provider for AI?
PostgreSQL is useful as a Knowledgebase provider when enterprises need both semantic retrieval and structured query control. With pgvector, Postgres can store embeddings and run vector similarity search. With SQL, it can also apply filters, joins, typed columns, metadata constraints, and access-control logic that pure vector stores do not handle natively.
How does PostgreSQL support vector search?
PostgreSQL supports vector search through the pgvector extension. In the Karini AI Postgres Knowledgebase provider, embeddings are stored as vector columns and searched using cosine similarity. HNSW indexes are used to accelerate vector retrieval for interactive agent and RAG workloads.
What types of data can the PostgreSQL Knowledgebase provider ingest?
The provider supports both document and tabular ingestion. For documents, it supports chunking, page numbers, chunk IDs, raw chunk tracking, and bulk embedding generation. For tabular data, it supports dynamic table creation with typed columns, including text, integer, float, boolean, JSONB, and vector types.
How does the Postgres Knowledgebase provider support hybrid retrieval?
The provider supports hybrid retrieval by combining semantic similarity with structured SQL filters, joins, metadata constraints, and ranking logic in a single query. This allows teams to retrieve relevant documents while also enforcing business-specific filters such as contract value, project type, region, access permissions, or other structured attributes.
When should enterprises choose PostgreSQL instead of a dedicated vector database?
Enterprises should choose PostgreSQL when their data is already relational, when they want one operational footprint for structured and unstructured retrieval, or when retrieval requires SQL-level control over filters, joins, access controls, and ranking. A dedicated vector database may still be better for workloads focused only on large-scale semantic search over documents.
How does PostgreSQL compare with OpenSearch and Azure AI Search in Karini AI?
PostgreSQL is best for combining unstructured documents and tabular data in one SQL-native database. OpenSearch is best for full-text and hybrid search at scale with rich query DSL support. Azure AI Search is best for managed vector search in Azure environments. Karini AI supports multiple Knowledgebase providers so enterprises can choose the right provider by workload.
Can PostgreSQL be used for RAG workflows in Karini AI?
Yes. In Karini AI, a PostgreSQL Knowledgebase can be used as a Knowledgebase node inside a RAG workflow. The agent retrieves grounded context from Postgres as part of its reasoning process, while users see retrieval status indicators that keep the workflow observable.
Can PostgreSQL be used as an Agentic tool?
Yes. The same PostgreSQL Knowledgebase can be exposed as an Agentic tool. An AI agent can call the tool on demand, pass a natural-language query, generate embeddings, retrieve ranked results, and return grounded context. Advanced users can also supply SQL query templates for more precise control over joins, filters, and ranking.
How does the provider handle access control?
The provider supports ACL-based access control using JSONB tags and metadata filtering. Access controls can be applied at the document or row level, allowing retrieval to respect the invoking user’s permissions, group memberships, and tenant boundaries.
Does the provider support multi-tenancy?
Yes. Multi-tenancy can be supported through ACL tags on shared tables or through separate databases per tenant. The right model depends on the customer’s security, isolation, and operational requirements.
Does the PostgreSQL Knowledgebase provider require pgvector?
Yes. The provider requires a PostgreSQL instance with the pgvector extension installed. pgvector enables Postgres to store embeddings and perform vector similarity search alongside structured data.
What indexing method does the provider use for vector search?
The provider uses HNSW indexing to accelerate vector search. The article describes HNSW defaults including m=16 and ef_construction=200, with configurable embedding dimensions depending on workload requirements.
What are the main benefits of using Postgres as a Knowledgebase provider?
The main benefits are one database for all data shapes, SQL-native retrieval precision, operational continuity for teams already running Postgres, first-class tabular support, production-grade vector search, and direct integration into Karini AI agents as both a Knowledgebase node and an Agentic tool.
What does “from two datastores to one” mean?
“From two datastores to one” means enterprises no longer need to stitch together a separate vector database for document retrieval and a relational database for structured data. With PostgreSQL, pgvector, and Karini AI, documents, tables, embeddings, filters, joins, metadata, and access controls can live in one retrieval layer.




